About Me
Introduction
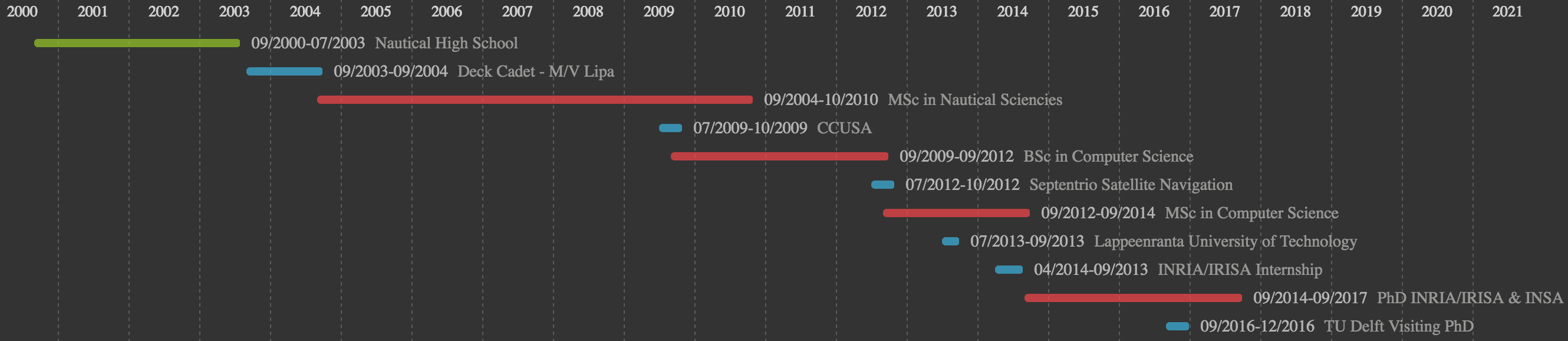
I'm a third year PhD student at INRIA/IRISA Rennes and INSA Rennes (France) working in deep learning methods to obtain and use multimodal representations in multimedia.
Previous to that, I obtained a MSc in computer science at the Faculty of Electrical Engineering and Computing in Zagreb and a MSc in nautical sciences at the Faculty of Maritime Studies in Rijeka (Croatia). Related to my nautical education, I'm also an Officer of the Watch (OOW) on ships of 3000GT or more that loves the sea but can't live without some R&D.
Current Professional Interests
My main interest is in applying different unsupervised or supervised deep learning methods to obtain well performing representations of single modalities (text, images, audio, etc.) and to find ways to fuse multiple single modalities into a better performing multimodal representation.
Typically, when working with single modalities, I'm prone to using:
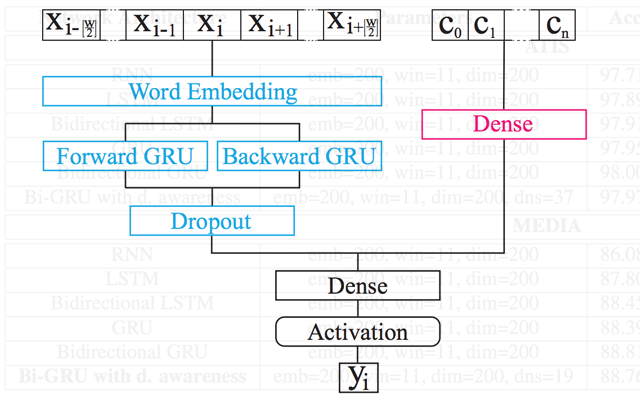
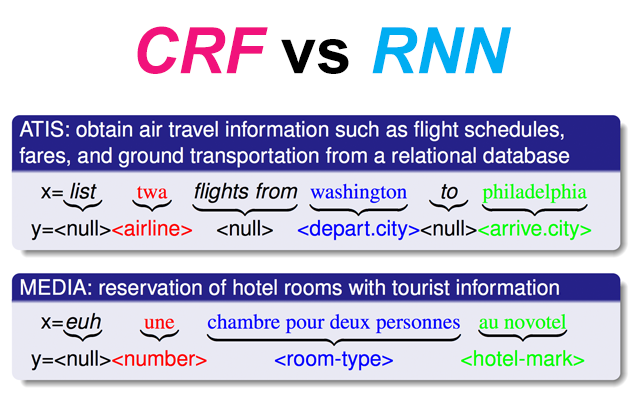
- Recurrent Neural Networks (RNNs) and Gated Recurrent Neural Networks (LSTM, GRU) - for modeling or generating text sequences and/or their respective tasks (e.g. in Spoken Language Understanding / Slot Tagging)
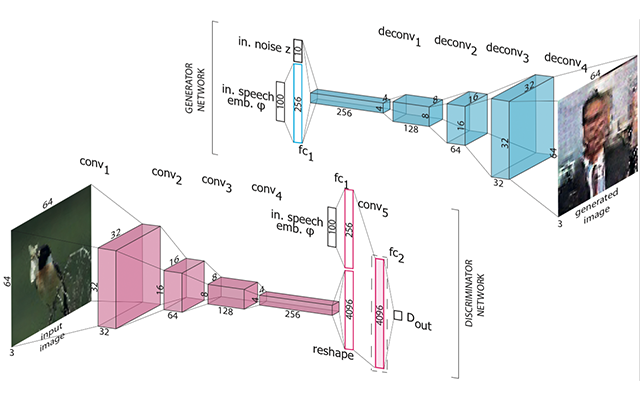
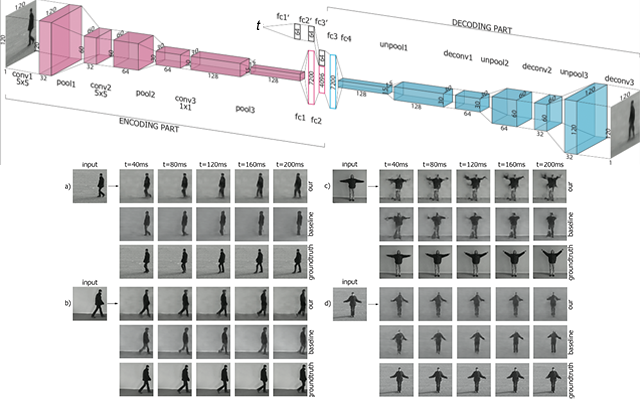
- Convolutional Neural Networks (CNNs) - for obtaining visual concepts (e.g. ImageNet concepts), high level image representations or low level, SIFT like representations. Transposed convolutions, also know as "deconvolutions" are something I've found quite useful on multiple occasions for synthesizing back in the original spatial domain and create synthetic images, either stand-alone or as part of Generative Adversarial Networks.
- Word embeddings like Word2Vec or document/paragraph embeddings like Paragraph Vectors - for representing speech or part of speech segments
For combining multiple modalities, I prefer multimodal fusion to combining scores or reranking by different modalities. More specifically:
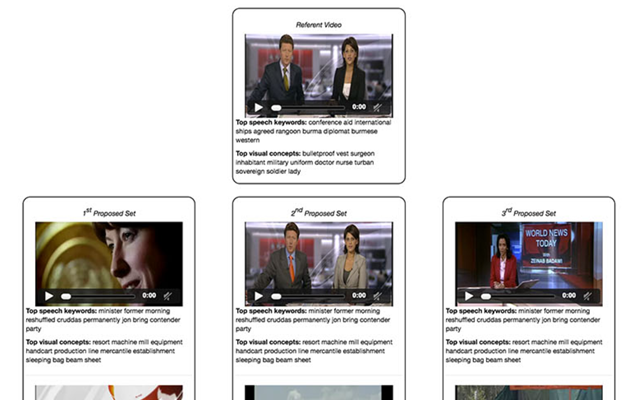
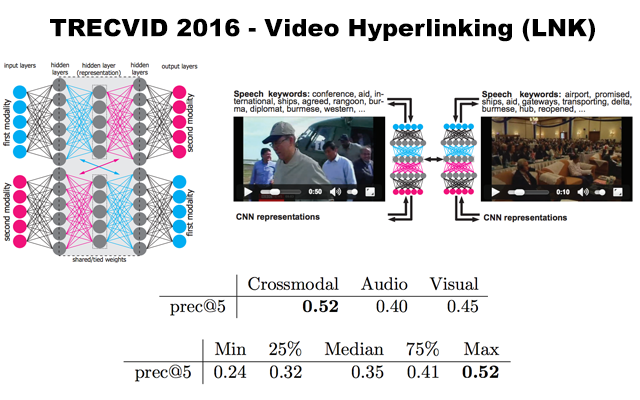
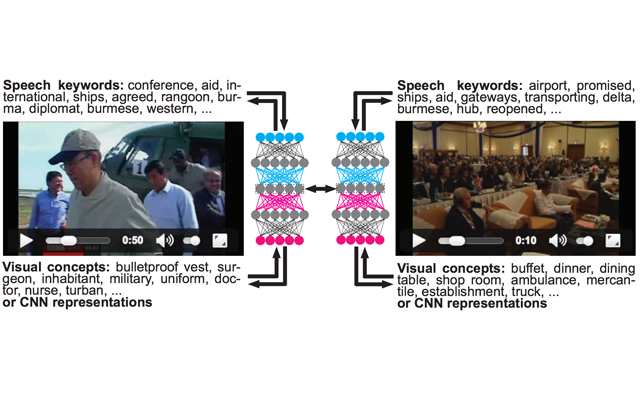
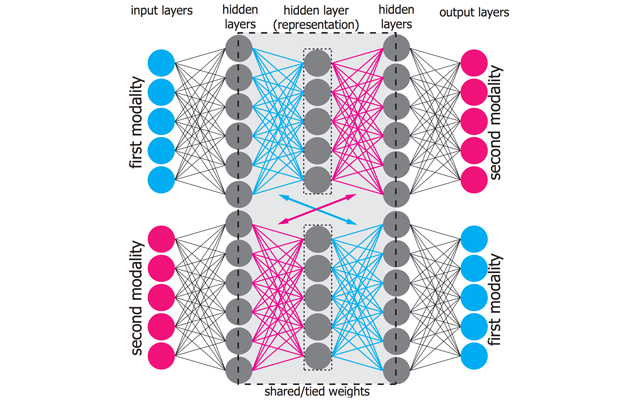
- I've found that using crossmodal translations with additional restrictions instead of classical multimodal autoencoders results in fused multimodal representations of improved quality. This was proven in multiple setups and, later on, also in a live evaluation at TRECVID's video hyperlinking challenge, were the crossmodal fusing method achieved the best results.
- When working with multiple modalities, there are different interesting choices for possible domains in which a modality can be represented: i) original space (e.g. spatial domain or text domain), ii) concept space (e.g. visual concepts or speech keywords) and iii) continuous representations spaces (e.g. CNN features, Word2Vec). While it's clear that fused continuous representations achieve the state of the art and that they have amazing properties, they might not be easily to visualize to a human observer (despite t-SNE). It's thus interesting to try to learn from the original space and synthesize back to it. This is were Generative Adversarial Networks excel at. Despite their computational complexity, I've found them not only be capable of learning representations spaces that outperform previous methods but also to provide nice visualizations that can help a human gain insights in the trained model.
Other Interests
I'd like to describe myself as an avid DIY-er that can be found doing anything, from soldering a CPLD or shaping a fountain out of polyurethane foam to welding a bench. I think that our innate curiosity should be nurtured and be allowed to grow.
The things I'm most passionate about include DIY digital electronics, open source, unix systems, wood and metalwork. I'm a big fan of non-competitive outdoor sports such as hiking, vertical caving, scuba diving and potentially many others, where we enjoy the environment all together and return home with nice memories and photos.
Orthographic Projection

Education/Work Timeline