Abstract
Architectures of Recurrent Neural Networks (RNN) recently become a very popular choice for Spoken Language Understanding (SLU) problems; however, they represent a big family of different architectures that can furthermore be combined to form more complex neural networks. In this work, we compare different recurrent networks, such as simple Recurrent Neural Networks (RNN), Long Short-Term Memory (LSTM) networks, Gated Memory Units (GRU) and their bidirectional versions, on the popular ATIS dataset and on MEDIA, a more complex French dataset. Additionally, we propose a novel method where information about the presence of relevant word classes in the dialog history is combined with a bidirectional GRU, and we show that combining relevant word classes from the dialog history improves the performance over recurrent networks that work by solely analyzing the current sentence.
Overview
In this work we do two things: i) we evaluate different (gated and non-gated) recurrent neural network architecture, modeling sequences either in one or both directions, in the task of slot tagging / spoken language understanding, and ii) we try to model key concepts of the dialog to make the network aware of crucial past information.
We evaluate the following RNN architectures:
- a simple RNN cell - the basic RNN model, with one recurrent loop and nothing more
- LSTM - Long Short Term Memory networks, the most popular gated recurrent architecture
- GRU - Gated Recurrent Unit, a recent simplification of LSTMs that is easier to train and achieves better results
Each architecture is tasted in two setups:
- sequence modeling in one direction, more precisely, just in the forward direction
- bidirectional modeling - forward and backward
A bidirectional architecture can be modeled directly by adding weights in the other direction (sometimes done for RNNs) or it can be just two architectures working in opposing directions (usually done with all more complex architectures in most frameworks).
We additionally test each setup on two datasets:
- ATIS - the famous/standard air traffic information dataset
- MEDIA - a less know but more complex, French dataset that contains touristic / reservation scenarios
In the last part, we try to model key concepts of the dialog. We model this as an additional vector that is presented with each word as input. The vector is binary and each element indicates whether a concept has been mentioned from the beginning of the dialog up to the current word. For ATIS, we model 19 concepts (e.g. aircraft_code, airline_code, airline_name, airport_code, airport_name, city_name, class_type, cost_relative, country_name, day_name, etc.) while for MEDIA, we model 37 concepts. The architecture combines a bidirectional GRU that models the input sequence with a fully connected dense layer that models the dialog concepts and a fully connected dense layer that merges the two and produces the output label y:
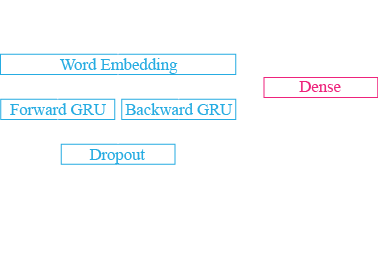
The results are as follows:
| Model | F1 (%) | Std. dev. (%) |
|---|---|---|
| ATIS | ||
| RNN | 94.63 | 0.14 |
| LSTM | 95.12 | 0.17 |
| Bidirectional LSTM | 95.23 | 0.11 |
| GRU | 95.43 | 0.06 |
| Bidirectional GRU | 95.53 | 0.17 |
| Bidirectional GRU + dialog aw. | 95.54 | 0.16 |
| MEDIA | ||
| RNN | 78.46 | 0.45 |
| LSTM | 81.54 | 1.33 |
| Bidirectional LSTM | 83.07 | 0.37 |
| GRU | 83.18 | 0.47 |
| Bidirectional GRU | 83.63 | 0.16 |
| Bidirectional GRU + dialog aw. | 83.89 | 0.27 |
And we can conclude the following:
- LSTMs outperform simple RNNs (quite obvious) and GRUs outperform LSTMs (which is really an additional confirmation of the capabilities of this new architecture)
- modeling in both directions is better than modeling just in one direction
- adding information of key concepts can help, especially in MEDIA where there is length dialog and not just one sentence
- and last but not least: ATIS is not a good dataset to test new methods, when computing a single-sided T-test, it's impossible to obtain an acceptable level of significance. Experiments performed on ATIS cannot be proven to be significant (by statistical means, using the word "significant" without performing a significance test does not count), which is unfortunate as this dataset is the de facto standard for the task.