Abstract
Video hyperlinking is the process of creating links within a collection of videos to help navigation and information seeking. Starting from a given set of video segments, called anchors, a set of related segments, called targets, must be provided. In past years, a number of content-based approaches have been proposed with good results obtained by searching for target segments that are very similar to the anchor in terms of content and information. Unfortunately, relevance has been obtained to the expense of diversity. In this paper, we study multimodal approaches and their ability to provide a set of diverse yet relevant targets. We compare two recently introduced cross-modal approaches, namely, deep auto-encoders and bimodal LDA, and experimentally show that both provide significantly more diverse targets than a state-of-the-art baseline. Bimodal autoencoders offer the best trade-off between relevance and diversity, with bimodal LDA exhibiting slightly more diverse targets at a lower precision.
Overview
Anca, a former colleague at Linkmedia was an avid proponent of diversity in video hyperlinking. I agree with her: video hyperlinking is a specific kind of multimodal retrieval where precision is only half the story, with the other half being diversity. In video hyperlinking, retrieving the most similar videos to a referent one does not make sense if they're all too similar. A proposed set of videos should be relevant and yet with enough variance to be as interesting as possible to the viewer.
We had different methods to perform video hyperlinking and so we decided to evaluate how they perform in terms of diversity (we already knew how they performed in therms of relevance/precision), so we chose three methods:
- a naive baseline - prepared by Remi that utilizes solely transcripts for retrieval
- BiLDA - a classical approach with a bimodal LDA model for video hyperlinking, developed by Anca towards the end of her PhD and unfortunately published only in this paper
- BiDNN - my deep learning approach to multimodal retrieval by using crossmodal translations with added restrictions to perform multimodal embedding
We're not allowed to use Amazon's mechanical turk or similar services, so I developed an online questionnaire and we asked members of the lab and members of the hyperlinking community to help us out. The questionnaire consisted of 16 questions but it was possible to complete it partially (due to questions in a shuffled order to provide a uniform number of submissions per question). Each question consisted of a given video (called an anchor in video hyperlinking terms) and three sets of proposed relevant videos. People were asked to rank the three sets of proposed videos by how diverse they seemed to them. Ranking was done by assigning unique "most diverse", "midly diverse" and "least diverse" values to the three proposed sets. The sets were obviously also shuffled each time.
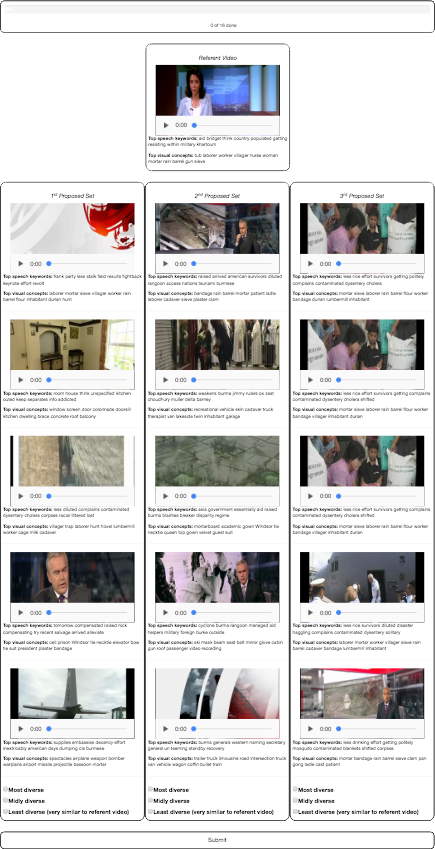
To better monitor the progression, I also created a small page with live statistics computed from the current submissions. It was interesting to see (even before analysis) that the results were quite consistent with a lower number of submissions and later on, after all the submissions when any personal difference was averaged out.
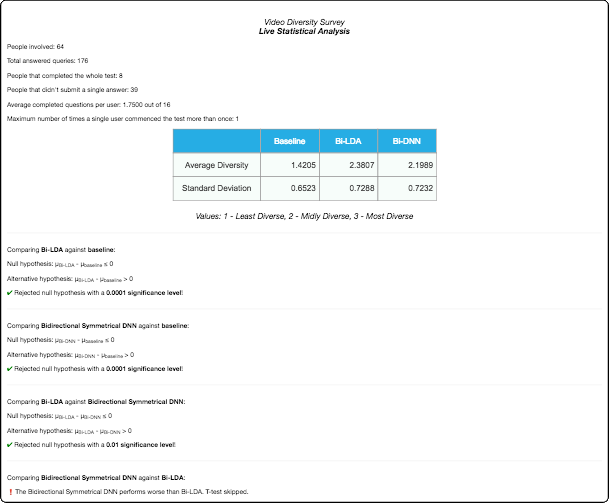
The final results were good. Anca's BiLDA performed best in terms of diversity, my BiDNN approach performed slightly less well but still comparable and the single-modal baseline, obviously performed significantly less good than multimodal approaches. Given that BiDNN achieves the state of the art in terms of relevance and it was solid in terms of diversity, I think it presents a good choice to perform video hyperlinking allowing for a win-win in terms of both relevance and diversity.
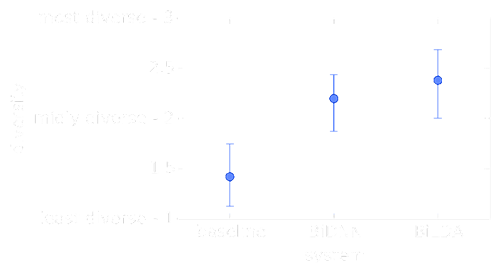
Remi analyzed diversity in an "intrinsic", numerical way and his results were consistent with the results from the questionnaire. This is a very nice observation given that analyzing diversity numerically (as variance) is easy and does not require human evaluation.