Abstract
This paper presents the runs submitted to the TRECVid Challenge 2016 for the Video Hyperlinking task. This task aims at proposing a set of video segments, called targets, to complement a query video segment defined as anchor. The 2016 edition of the task encouraged participants to use multiple modalities. In this context, we chose to submit four runs in order to assess the pros and cons of using two modalities instead of a single one and how crossmodality differs from multimodality in terms of relevance. The crossmodal run performs best and obtains the best precision at rank 5 among participants
Overview
Our team, Linkmedia, is a regular participant at Medieval's and now TRECVID's Video Hyperlinking Task (any many others). This year I also participated, and thus had the opportunity to test "live" (with human-based evaluation instead of a fixed groundtruth with predetermined video segment) my BiDNN method and see if it will live to the results it was able to achieve "offline" (on groundtruths from previous years).
Video hyperlinking or multimodal retrieval with BiDNNs is quite straight forward and performed completely in an unsupervised manner. Two crossmodal translations (each perfumed with an autoencoder like DNN) are formed between the two modalities, one translating from the speech representation space to the visual one and the other, translating from the visual representation space to the speech one. An additional restriction is place to enforced symmetry in the central part: the central weights of one network should be the transposed weights of the other network. The representation space in the middle tries to be a common representation space for both translations and serves as a multimodal representation space. Multimodal fusion is performed by translating each modality to this new space and concatenating them. In case one modality is missing, only the existing modality is translated to the new embedding space and the resulting vector is duplicated (to obtain a vector of the same size - this is possible as the new space is in common for both modalities). The method was introduced and described here and extensively evaluated and explained in the context of video hyperlinking here. Roughly, the system works by first learning a model, in an unsupervised manner, by doing crossmodal translations (speech to visual and visual to speech) for every possible video segment. Afterwards, for every video segment, the two modalities are fused into a new representation space that serves to compute similarities with other video segments:
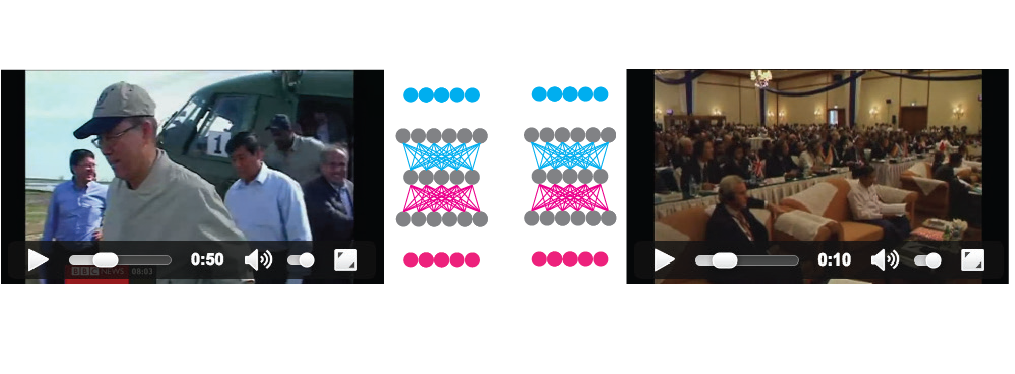
The 4 runs we submitted were:
- a BiDNN run - fusing Word2Vec speech features with VGG-19 high level features, in the standard BiDNN crossmodal fashion
- a speech only run - based solely on the Word2Vec speech features, to see how much does BiDNN improve over it
- a visual only run - based solely on VGG-19 features, kindly computed by Ronan, to see how much does BiDNN improve over them and the previous speech features
- a classical multimodal run - created by Remi by using classical methods and linear score fusion to compare against the BiDNN crossmodal way of performing multimodal fusion
The results were very good and BiDNN achieved the new state of the art and performed best. It was nice to see that BiDNN works well also in a live, human evaluated, setup, as it was previously tested only on fixed groundtruths. The single modalities obtained 40% (speech) and 45% (visual) and multimodal fusion improved the result for quite a significant gap to 52%. Quite a good empirical proof that focusing on crossmodal translations to improve multimodal fusion is the right way to go.
| Method | Precision at 5 |
|---|---|
| BiDNN fusion | 0.52 |
| Speech only | 0.40 |
| Visual only | 0.45 |
| Classical multimodal | 0.34 |
| Max (all teams) | 0.52 |
| Upper quartile (all teams) | 0.41 |
| Median (all teams) | 0.35 |
| Lower quartile (all teams) | 0.32 |
| Min (all teams) | 0.24 |