Abstract
Video hyperlinking represents a classical example of multimodal problems. Common approaches to such problems are early fusion of the initial modalities and crossmodal translation from one modality to the other. Recently, deep neural networks, especially deep autoencoders, have proven promising both for crossmodal translation and for early fusion via multimodal embedding. A particular architecture, bidirectional symmetrical deep neural networks, have been proven to yield improved multimodal embeddings over classical autoencoders, while also being able to perform crossmodal translation.
In this work we focus firstly at evaluating good single-modal continuous representations both for textual and for visual information. Word2Vec and paragraph vectors are evaluated for representing collections of words, such as parts of automatic transcripts and multiple visual concepts, while different deep convolutional neural networks are evaluated for directly embedding visual information, avoiding the creation of visual concepts. Secondly, we evaluate methods for multimodal fusion and crossmodal translation, with different single-modal pairs, in the task of video hyperlinking. Bidirectional (symmetrical) deep neural networks were shown to successfully tackle downsides of multimodal autoencoders and yield a superior multimodal representation. In this work, we extensively tests them in different settings with different single-modal representations, within the context of video hyperlinking. Our novel bidirectional symmetrical deep neural networks are compared to classical autoencoders and are shown to yield significantly improved multimodal embeddings that significantly (alpha=0.0001) outperform multimodal embeddings obtained by deep autoencoders with an absolute improvement in precision at 10 of 14.1% when embedding visual concepts and automatic transcripts and an absolute improvement of 4.3% when embedding automatic transcripts with features obtained with very deep convolutional neural networks, yielding 80% of precision at 10.
Overview
Previously, we introduced BiDNN, a variation of multimodal autoencoders where two crossmodal translations with added restrictions are used to perform multimodal fusion. For ACM's Multimedia 2016 Workshop - Vision and Language Integration Meets Multimedia Fusion, we extended that work and tested different initial single-modal representations for both text and video as well as how different ways of combining them perform. The best performing setups from this work are the one later used at TRECVID's 2016 video hyperlinking task, where we obtained the best score and defined the new state of the art.
In the first part of this work, we analyze different single-modal representations for video hyperlinking. We valuate different ways to embed visual concepts and different CNN architectures for representing video keyframes, namely AlexNet, VGG-16 and VGG-19 and we evaluate Word2Vec and paragraph vectors for representing speech segments, as well as different aggregation methods for both modalities. The results are as follows:
| Representation | Aggregation | Precision @ 10 (%) |
|---|---|---|
| Automatic speech transcripts | ||
| Word2Vec | average | 58.67 |
| Word2Vec | Fisher | 54.00 |
| PV-DM | - | 45.00 |
| PV-DBOW | - | 41.67 |
| Visual information | ||
| Visual Concepts, W2V | average | 50.00 |
| Visual Concepts, PV-DM | - | 45.33 |
| Visual Concepts PV-DBOW | - | 48.33 |
| AlexNet | average | 63.00 |
| AlexNet | Fisher | 65.00 |
| VGG-16 | average | 70.67 |
| VGG-16 | Fisher | 64.67 |
| VGG-19 | average | 68.67 |
| VGG-19 | Fisher | 66.00 |
It was surprising to see that averaging Word2Vec representations of each word in a speech segment outperforms paragraph vectors (or at least their implementation in gensim). On the other side, for the visual modality, it came as no surprise that aggregated VGG-19 features performed best. Aggregated Word2Vec and VGG-19 features are thus also what we used later at TRECVID 2016. Now, it's time to address methods of fusing those two modalities.
Typically, multimodal fusion of disjoint single-modal continuous representations is performed by multimodal autoencoders. Two types of autoencoders are often used: i) a simple autoencoder (illustrated below, on the left) that is typically used for dimensionality reduction of a single modality but is here presented with both modalities concatenated at its input and output and ii) a multimodal autoencoder containing additional separate branches for each modality (illustrated on the right). With all autoencoders, noise is often added to the inputs in order to make them more robust. In the case of multimodal autoencoders, one modality is sporadically zeroed at input while they're expected to reconstruct both modalities at their output.
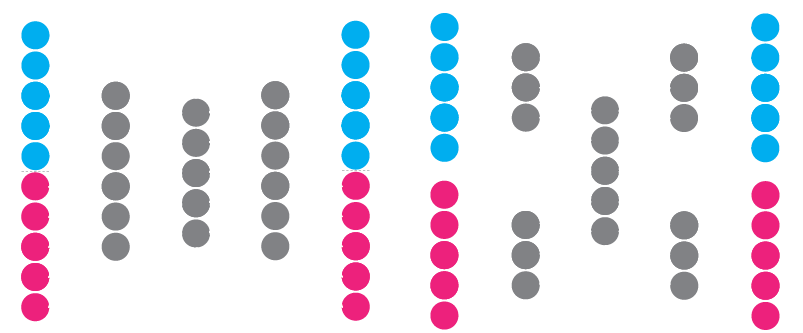
In my opinion, there are a few downsides to using classical autoencoders to perform multimodal fusion:
- Both modalities influence the same central layer(s), either directly or indirectly, through other modality-specific fully connected layers. Even when translating from one modality to the other, the input modality is either mixed with the other or with a zeroed input.
- Autoencoders need to learn to reconstruct the same output both when one modality is marked missing (e.g., zeroed) and when both modalities are presented as input.
- Classical autoencoders are primarily made for multimodal embedding while crossmodal translation is offered as a secondary function.
With the BiDNN architecture, we aim at tackling those downsides and focus on crossmodal translation as a mean to obtain multimodal fusion. The architecture consists of two neural networks translating the two modalities, one translating the visual representation into speech representation and the other translating the speech representation into visual. In the central part, the weights of the two networks are shared (the weights of one network are the same weights of the other network transposed) to enforce additional symmetry and create a common representation space that's common for both modalities. More details about the architecture are explained in the previous paper.

Video hyperlinking (multimodal retreival) is done by first learning a model, in an unsupervised manner, by doing crossmodal translations (speech to visual and visual to speech) for every possible video segment. Afterwards, for every video segment, the two modalities are fused into a new representation space that serves to compute similarities with other video segments:
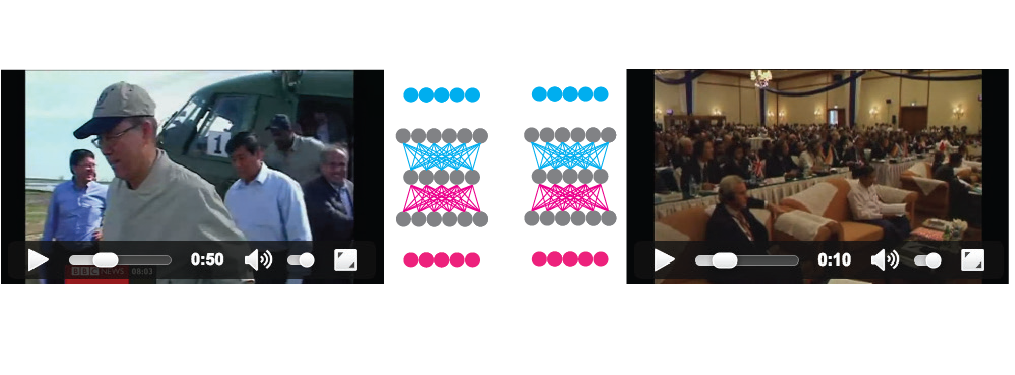
The results are as follows:
| Modalities | Method | Precision @ 10 (%) | Std. dev. (%) |
|---|---|---|---|
| Simple multimodal approaches | |||
| Transcripts, v.c. | concat | 58.00 | - |
| Transcripts, AlexNet | concat | 70.00 | - |
| Transcripts, VGG-16 | concat | 75.33 | - |
| Transcripts, VGG-19 | concat | 74.33 | - |
| Transcripts, v.c. | linear comb. | 61.32 | 3.10 |
| Transcripts, AlexNet | linear comb. | 67.87 | 2.66 |
| Transcripts, VGG-16 | linear comb. | 71.86 | 4.11 |
| Transcripts, VGG-19 | linear comb. | 71.78 | 3.90 |
| Multimodal autoencoders | |||
| Transcripts, visual concepts | 59.60 | 0.65 | |
| Transcripts, AlexNet | 69.87 | 1.64 | |
| Transcripts, VGG-16 | 74.53 | 1.52 | |
| Transcripts, VGG-19 | 75.73 | 1.79 | |
| BiDNN embedding of single modalities | |||
| Transcripts | 66.78 | 1.05 | |
| Visual concepts | 54.92 | 0.99 | |
| AlexNet | 66.33 | 0.58 | |
| VGG-16 | 68.70 | 1.98 | |
| VGG-19 | 70.81 | 1.08 | |
| BiDNN multimodal fusion | |||
| Transcripts, visual concepts | 73.78 | 0.46 | |
| Transcripts, AlexNet | 73.41 | 1.08 | |
| Transcripts, VGG-16 | 76.33 | 1.60 | |
| Transcripts, VGG-19 | 80.00 | 0.80 | |
In the first part, we analyze two simple methods of combining two modalities: (normalized) concatenation and linear score fusion (score combination). In the second part we evaluate a multimodal autoencoder (with separate branches) for all the single modalities.
In the third part, we evaluate how a single modality improves when embedded into the new representation space with BiDNN. So, the model was still trained in an unsupervised manner with both modalities but now, only one modality is embedded (we use just one of the two crossmodal DNNs and take the output of the middle layer). Transcripts improve from their initial 58.00% to 66.78% and VGG-19 visual features improve from 68.67% to 70.81% just from being embedded into the new space.
In the forth and last part, we evaluate BiDNN multimodal fusion. Fusing the modalities bring the biggest improvement and the best result was achieved by fusing Word2Vec speech features (58.00%) and VGG-19 visual features (68.67%) with the quite impressive resulting precision at 10 of 80.00%