Abstract
There is an inherent need for machines to have a notion of how entities within their environment behave and to anticipate changes in the near future. In this work, we focus on anticipating future appearance given the current frame of a video. Typical methods are used either to predict the next frame of a video or to predict future optical flow or trajectories based on a single video frame.
This work presents an experiment on stretching the ability of CNNs to predict an anticipation of appearance at an arbitrarily given future time. We condition our predicted video frames on a continuous time variable that allows us to anticipate future frames at a given temporal distance, directly from the current input video frame.
We show that CNNs can learn an intrinsic representation of typical appearance changes over time and successfully generate realistic predictions in one step at a deliberate time difference in the near future. The method is evaluated on the KTH human actions dataset and compared to a baseline consisting of an analogous CNN architecture that is not time-aware.
Overview
While at TU Delft, Silvia and I talked many times about motion prediction and DejaVu, her motion predictor based on a structured random forest.
Thinking of ways to predict motion in the spatial domain with deep learning methods, I thought that the best easiest approach would be to perform iterative convolutions and "deconvolutions" to synthesize a motion prediction time t0 + Δt from the original image at time t0, then use that synthetic image to predict motion at time t0 + 2 Δt and so on. Eventually modeling time better by adding RNNs and so on.
At ECCV 2016, a poster caught my attention (well, many did, but this one in particular). The poster was named "Multi-view 3D Models from Single Images with a Convolutional Network" and the authors were showing a nice synthetic 3D car rendered at an arbitrary angle from an input picture of the car. They were using just an encoder -decoder, convolution - "deconvolution" network, with a separate branch to provide the desired angle as input. I would have thought that to be a little bit too much to ask a simple architecture as that, but apparently, it was not. I immediately thought that if they scratch the ability of such an architecture to predict images (well, RGBD data in their case) from a single image, at an arbitrary angle, I should be able to use an analogous architecture to predict future motion directly, at an arbitrary timestamp. After returning from ECCV, I've started implementing a similar architecture in TensorFlow to test the idea ASAP.
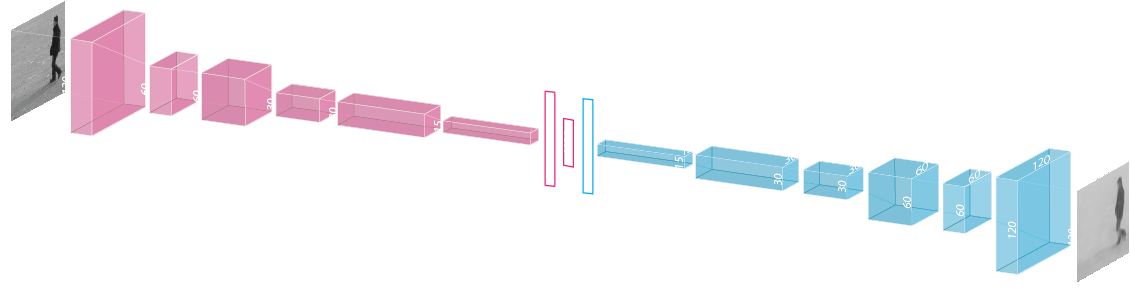
The architecture consists of:
- an image modeling branch - consisting of a CNN network that models the input image into a useful internal representation
- a time modeling branch - consisting just of fully-connected layers. I initially thought of embedding time (with a LUT) but that would discretize the time intervals and, as discussed later on, this way we can predict motion at completely arbitrary time intervals.
- a decoding branch - consisting of a "deconvolution" network that synthesizes the prediction in the original spatial domain, at the desired time t
The results ended up being quite good:

Given an input image (on the left) and a time t (on top), the network directly synthesizes an image that predicts the motion after time t. In a) we see a person walking on the left. The network correctly predicts images where the location of the person is displaced to the left and the body movements seem appropriate. In b) the person is moving to the right. The network is again correctly predicting the location of the person displaced to the right and appropriate body movements. In c) we see a person hand-waving and the prediction that, although with some artifacts, predicts correctly. In d) the person is slowly hand-clapping. The results are again similar.
As expected, the iterative network that we chose for a baseline ceases to work after a few iterations, necessary to arrive at time t, while our network predicts motion directly and correctly.
The results are nice also for longer temporal distances t, though an increasing deterioration is clearly visible:

The interesting thing about this architecture is its ability to predict at arbitrary time differences. During training, only discrete intervals dictated by the video framerate are available. The network, however, has no problem generalizing and predicting at either intra-intervals or extrapolate behind the last one:

More evaluations, not only visual but also through MSE scores are available in the paper. However, not everything works well. The major encountered issues are:
- Human Pose Ambiguities - Ambiguities in body-pose happen when the subject is in a pose that does not display inherent information about the movement of the subject in question. A typical example would be when a person is waving, moving their arms up and down, and an image with the arms at a near horizontal position is fed to the network as input. A more extreme case is shown in a) where not only does the network predict the movement wrong, upward instead of downward, but it also generates a lot of artifacts with a significant loss of details that increases with the time difference t.
- Fast Movement - Fast movement causes extreme loss of details when the videos provided for training do not offer a high-enough framerate. In other words, this case happens when the visual difference between two consecutive frames during training is substantial - large global displacement and a body pose change that are too large. Examples of this can be seen in b) and c) where the increased speed in jogging and an even more increased speed in running generate significant loss of details. It is important to emphasize that although our proposed architecture can generate predictions at arbitrary time intervals t, the network is still trained on discretized time intervals derived from the videos --- intervals that might not be small enough for the network to learn a good motion model. We believe this causes the loss of details and artifacts, and using higher framerate videos during training would alleviate this.
- Insufficient Foreground / Background Contrast - Decreased contrast between the subject and the background describes a case where the intensity values corresponding to the subject are similar to the ones of the background. This leads to a automatic decrease of MSE values and a more difficult convergence of the network for such cases, which leads to less adaptation and thus to loss of details and artifacts. This can be seen in d). Such effect would be less prominent in case of modeling a network using color images.
- Excessive Localization of Movements - Excessive localization of movements happens when the movements of the subject are small and localized. A typical example is provided by the boxing action, as presented in the KTH dataset. Since the hand movement is close to the face and just the hand gets sporadically extended - not a considerable change given the resolution of the images - the network has more difficulties in tackling this. Despite the network predicting feasible movement, often artifacts appear for bigger time intervals t, as visible in e).

Although the previously enumerated cases can lead our proposed architecture to predict that display loss of details and artifacts, most can be tackled and removed if necessary by either increasing the framerate, the resolution of the training videos, or using RGB information. The most difficult factor to overcome is human pose ambiguity, which is a hard problem for our proposed architecture to manage